{kind=link}

PhDr. Mgr. Jeroným Klimeš, Ph.D. 2021-08-17
jeronym.klimes@seznam.cz
www.klimes.us
V časopise Hamík vyšel článek o tomto programu na pokračování 1. část 2. část
Předesílám, že v morseovce jsem naprostý amatér a dostal jsem se k ní jako slepý k houslím, příběhem popsaným níže. Profesionální stránky na toto téma naleznete třeba zde: https://telegrafie.cz/
Příběh na začátku
Tento program vznikl zcela neplánovaně. Byl u nás na návštěvě syn ženiny kamarádky a nějak z něho vylezlo, že se učí morseovku. Řekl jsem si, že to nemůže být nic složitého, a že by si to mohli kluci zkusit naprogramovat v Bash - Linux. Ukázalo se, že to je mnohem složitější počin, než se prve zdálo. Už teď má ten program přes 1000 řádek.
Samozřejmě kdybych se rozhodoval napsat ten program od začátku, tak bych asi raději sáhl po Pythonu, nebo C, protože psát to v Bash je trochu zhůvěřilost. Ale když už to mám takto napsané, tak to předělávat nebudu. Bash je šílená zmatlanina historických reliktů, nedodělků a provizorních řešení, takže v něm programovat je trochu alchymie, ale má to své výhody - běží na každém počítači s Linuxem (Ubuntu, Kde, Mint ap.), nevyžaduje žádné mimořádné knihovny či speciální programy než ty, které lze stáhnout z běžných úložišť (sudo apt install ***). Z toho důvodu si může každý tento program upravit k obrazu svému, přenastavit si konstanty, vytvořit si vlastní cvičení ap.
Co se ale tak nějak samo podařilo bylo naprogramování jádra programu, který generuje samotné zvuky. Nakonec to neskládám z teček a čárek, ale napřed vytvořím jakýsi "skript" z parametrů a pomocí něho programem sox vytvořím zvukový soubor. Ten se pak přehrává, takže zvuk je hezky vyhlazený, pravidelný, jako by ho sázel profesionální radista. To je myslím největší přednost tohoto programu. Jedná se jmenovitě o proceduru Fmorseovka_hrani - vstup je morse kod (-..-), výstup zvukový soubor (.ogg).
Seznam souborů
Nutné
Volitelné
Github (kompletní a aktuální verze, tato stránka může být zastaralá)
https://github.com/xerostomus/morseovka/
Vlastní výuka Morseovy abecedy
Vlastní výuka je zároveň seznámení dětí s terminálem Linuxu a s příkazovou řádkou terminálu. Například jim hned na začátku vysvětlím, že co následuje za # je pouze komentář, který nemusejí opisovat. Rodičům doporučuji, aby učení morseovky zkombinovali s výukou psaní všemi deseti - každý den se naučí dvě tři písmena, které by měly psát vždy stejnými prsty, aby psaly rychle.
Program si stáhneme z GitHub úložiště jako dva soubory - shell script a obrázek znaků:
jkmorseovka.sh
jkmorseovka.png
Tento vysvětlovací soubor, popř. další nejsou nutné pro běh programu.
Napřed musíme nastavit spustitelnost scriptu:
chmod +x jkmorseovka.sh
Načež ho můžeme spustit a vyzkoušet, co z něj vypadne, tak vyzkoušíme podle toho, co bude fungovat:
./jkmorseovka.sh # nebo
jkmorseovka.sh
Program si napřed vyžádá instalaci pomocných programů: sox (výroba zvuků), bc (kalkulačka), feh (zobrazování obrázku). Dále napoví, že vyžaduje nějaké parametry:
jkmorseovka.sh --help
Nápověda se ukončuje písmenem q - quit a je v ní napsán celý postup, jak se morseovku učíme.
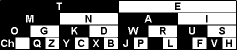
jkmorseovka.sh --vypis-znaku
Napřed se zcela povrchně seznámíme s mnemotechnickými frázemi, které napovídají morse znak, např. Kákorá -.-. Po ukončení nápovědy se zobrazí obrázek s tabulkou, která se čte vždy od shora dolu s tím, že černý proužek je čárka, bílý tečka. Takže když sestupujeme odshora k písmenu K podél šipky, tak máme černá - bílá - černá, čili "-.-".
Druhým krokem se nácvik po písmenech:
jkmorseovka.sh --pismena-vizualne cviceni1
Cviceni1 jsou jednoznakova pismene, čili E a T, která se vizuálně zobrazují, když se přehrávájí. To je dobré pro začátek, ale pak přecházíme na cvičení bez zrakové opory:
jkmorseovka.sh --pismena cviceni12
Toto cvičí jedno a dvou znaková písmena už jen sluchem, každopádně po třech chybách se objeví nápověda.
Exkurz: Savčí versus plazí mozek u morseovky a Kochova metoda
Začátečníky překvapuje informace, že vůbec není důležité, jestli si pamatují či nepamatují jednotlivé znaky, takže si mohou kdykoli říkat o nápovědu bez většího volního úsilí. Totiž učení morseovky není test inteligence či paměti. Tam necvičíme racionální savčí mozek či sílu vůle, ale je to drilování plazího mozku, aby se vytvořilo reflexní spojení mezi zvukem -.- a okamžitým stiskem klávesy K. Než toto reflexní spojení samo vznikne, musí se ten úkon zopakovat tisíckrát po dobu několika měsíců. Takže je jasné, že mezi tím byste se naučili racionálním savčím mozkem mnemotechnické zkratky stokrát, proto nás opravdu netrápí, že je na začátku dítě pořádně neumí.
Důsledek tohoto faktu je, že se hlava neučí analyticky rozebrat zvuk na dílčí čárky, tečky, ale měla by ho vnímat jako jeden celek, jako jedno slovo. Slovo prak taky v běžné řeči nerozkládáme na písmena - P-R-A-K. Stejně tak morse kódy se učíme jako celky, ne jako složeninu teček a čárek. Jakmile tedy hlava začne rozebírat: "Táty táta čili děda je písmeno Y, které je zrcadlově obrácené k písmenu Q, které zní jako nápěv z písně 'Saxano, v knihách vázaných v kůži'." Tak je přínak toho, že to analyzujeme savčím mozkem a ne plazím. To je dobré maximálně na zapamatování morse kódů, ale rozhodně ne na učení se morseovky pro vysílání a příjem textu. Naopak cílem je, aby na -.-- reagovala jen samotná "ruka" (tedy jen plazí mozek) stiskem klávesy Y a hlava nic jiného neanalyzovala.
Z tohoto důvodu je dobré, aby znaky byly hrány rychle a mezi ně, abychom raději vkládali delší pauzy, než abychom zpomalovali vlastní přehrávání morse kódu, to právě zapíná analytický savší mozek. U cvičení tedy prakticky vždy nastavujeme větší pauzu mezi písmeny, než je normovaná (1000 místo 100), ale by nevznikal časový stres. To je podstata tzv. Farnsworthovy komprese.
jkmorseovka.sh -o cviceni3a --mezi-pismeny 1000 --pocet-pismen 3
Rychlost samozřejmě můžeme také zpomalit parametrem "--rychlost 50", ale jak říkám není to doporučená praxe.
V nevýhodě jsou děti s ADHD, které při morseovce trápí zárazy - mnohem hůř vytvářejí stabilní reflexní spojení:
Zvuk → Pohyb prstu
Díky tomu mohou být později kreativnější a vynalézavější. Bohužel podmínkou nutnou kreativity je naučit se, přesněji řečeno nadrilovat se předem základy řemesla, což je pro ADHD děti utrpením. Ale holt takový je život. Nic není zadarmo.
Kochova metoda a časový skluz
O toto vypínání savčího mozku se snaží metoda, kterou Ludwig Koch vymyslel před válkou (1930) a která učí morseovku podobně, jako se děti téměř plné rychlosti učí rodný jazyk: "Pocem!" a ne "Pojď sem!". Napřed se v plné rychlosti učíme dvě písmena KM a pak pomalu přidáváme další, když chybovost poklesne pod 10 %, tzn. když už je vcelku vytvořené reflexní spojení. Kochův přístup vede k tomu, že od začátku se učíme poslouchat jedno písmeno a zároveň psát předposlední jaksi ve skluzu. Například máme-li text BFL. Když posloucháme B, nic nepíšeme. Když už poslouchápme písmeno F, tak píšeme předchozí B. Když posloucháme L, píšeme rozeznané F. Když skončilo vysílání, dopíšeme poslední L.
Osobně se domnívám, že pro lidi, kteří se chtějí jen naučit morseovu abecedu, trochu ji provičit, aby ji jen tak nezapomněli, ale dál se nechtějí améterskému radiu věnovat, tak stačí se naučit jen jednotlivá písmena pomocí parametru --pismena, popř. --pismena-vizualne. Prostě kdo analyzuje jen napsanou morseovku na papíře (telegraf, táborové hry), nemusí se učit psát písmena s latencí oproti poslouchanému zvuku. Pokud ale chtějí chytat 10 slov za minutu, tak musejí přejít na Kochovu metodu. Ovšem ta vyžaduje mnohem větší dril a delší učení, než pouhé naučení a procvičení písmen. Velice hezká stránka, která mě inspirovala, je tato: https://stendec.io/morse/koch.html.
Hlavní přednost Kochovy metody je, že odnaučí člověka využívat tzv. senzorický registr. Například, když slyšíte -.-, a nenaskočí vám automaticky písmeno K, tak si ten zvuk začnete přehrávat z tzv. senzorického registru, ve kterém jsou přibližně poslední dvě sekundy vnímaného zvuku či obrazu. Začnete si opakovat "-.- -.- -.-, čárka tečka čárka, co by to mohlo být?". Jenže to máte zapnutý jak senzorický registr, tak i racionální mozek a to je ke škodě. Když ale Kochova technika vás tlačí dopředu, naučíte se tento senzorický registr nevyužívat, ale to znamená, že se musí mnohem více zautomatizovat spojení 'slyšený kód → pismeno'.
Odvrácenou stranou Kochova přístupu bývá naopak časový stres, které působí časový skluz při zápisu písmen. U dětí, které jsou na to citlivé, proto dbáme na to, aby uvolnily zádové svaly (příznak stresu) a nebály se zapisovat, co slyšely, ne to, co právě poslouchají. To, co právě poslouchají, za ně automaticky analyzuje plazí mozek (někde v pravém spánkovém laloku - za pravým uchem), oni pak jen savčím mozkem zapisují, co slyšeli (frontální lalok za čelem posílá impulzy k Rolandově rýze, kde se vysílají impulzy ke svalům).
Je důležité vědět, že ve stresu přestává fungovat paměť, tedy děti vedeme k tomu, aby nebyly ve stresu. Ty, které upadají do velkého stresu z časového skluzu raději naučíme písmena v tak pomalém tempu, aby se v klidu správně rozpomněly na 90 % písmen. Nevadí, když se při pomalém tempu mají mikropauzy, v této "nudné mezidobě" totiž vzniká žádoucí reflexní spojení zvuk-pohyb prstu. Tedy jako u klavíru platí, čím pomaleji hraji, tím rychleji se učím. Je to jako s rozbruskou - čím méně tlačím na tenký řezný kotouč, tím rychleji řeže. Čím méně se snažím zvládnout partnerský rozchod silou vůle, tím dříve ho mám za sebou. Čím méně se snažím usnout, tím snadněji usnu. To vše jsou příklady paradoxů, které často lidem nedocházejí. Síla vůle není vždy optimální nástroj na řešení problému.
Tedy u Kochovy metody volíme --rychlost=120, aby písmena tvořila jednolitý akustický celek, zvýšíme prodlevu mezi písmeny --mezi-pismeny=400 (nyní výchozí hodnoty). Tuto prodlevu nastavujeme tak, abychom jednak nebyli v časovém stresu, ale také abychom nepoužívali senzorický registr. Dalším důležitým parametrem je počet písmen na vysílanou skupinu. Doporučuji pro začátečníky 5, aby si mohli po skupince písmen odpočinout a zrelaxovat. Jinak u Kochovy metody (koch#, postupne#, nahodne#) jsem nastavil 7 znaků právě s ohledem na Kochův požadavek 90% úspěšnosti. Jestliže totiž máme 7 písmen s pravděpodobností správné odpovědi 0,9, pak 0,9^7=0,48 čili přibližně 50 % pravděpodobnost, že uhodnete celou skupinku. Jakmile tedy vidíte, že skupinky po 7 písmenech určujete většinou správně, je načase přidat další písmeno.
Momentálně jsou v programu tři varianty, které vycházejí z Kochovy metody:
jkmorseovka.sh --cviceni koch2
jkmorseovka.sh --cviceni postupne2
jkmorseovka.sh --cviceni nahodne2
Všechny jsou nastaveny tak, že po pěti úspěšných, resp. neúspěšných pokusech přidají, resp. uberou znak.
Mnou preferovana varianta je:
jkmorseovka.sh --cviceni nahodne2
a to proto, že každý den začínám novou nahodilou sekvencí písmen a každý den začínám od nějaké dvojice, kterou se naučím distriminovat čili rozlišovat zcela reflexně. Když písmena znám a jdou mi dobře, tak program sám rychle zvyšuje počet písmen. Další den pak začínám s novými písmeny. To je výhoda počítače, který nahodilé pořadí vytvoří lusknutím prstu. Proto myslím, že tuto variantu Koch před válkou neuvažoval. T.č. je tato sekvence bez číslovek, pokud ale chcete jako Koch zahrnout i čísla, pak si upravte v programu proceduru Fnahodne (viz komentovaná řádka u příkazu shuf).
Postup při učení Kochovou metodou
jkmorseovka.sh --cviceni koch2
jkmorseovka.sh --cviceni koch2 --rychlost 130 --mezi-pismeny 500 --pocet-pismen 10 #ručně nastavené parametry
Když vidíte, že většinou skupiny 7 písmen hádáte správně, tak přidáte písmeno:
jkmorseovka.sh --cviceni koch3
Tak postupujete až do koch40, každopádně program tak činí sám po pěti po sobě jdoucích správných skupinách.
Pokud si ve skriptu nastavíte vlastní pořadí písmen (proměnná abeceda_postupne), pak můžete stejně nacvičovat vlastní cvičení:
jkmorseovka.sh --cviceni postupne2
A tak dále až do postupne40.
Neuropsychologické vysvětlení časového skluzu
Červeně je to, co se zjednodušeně označuje za plazí mozek, protože to měli již dinosauři čili i slepice. Zelené je savčí racionální mozek, vlastnost vcelku jen člověka. Na zpracování morseovky se můžeme podívat dvojmo, proto dva obrázky:
A) Co se postupně děje se zpracovávaným písmenem.
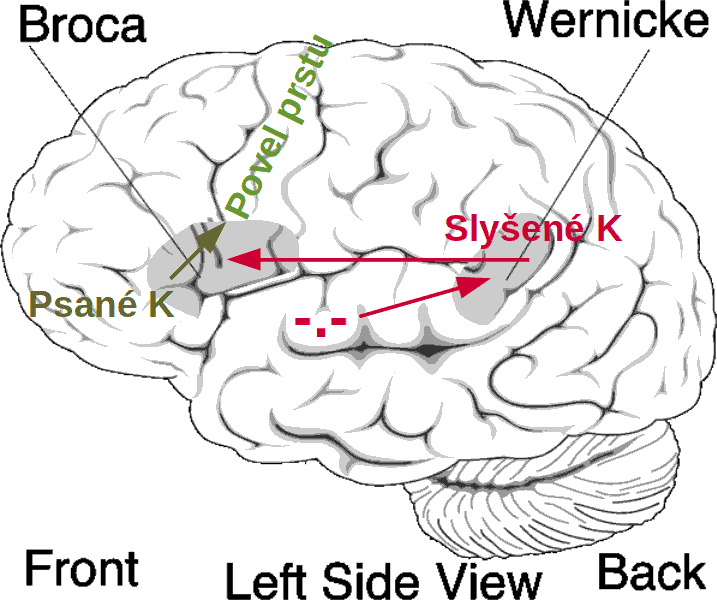
Ze sluchových center ve spánkovém laloku jde do pravé poloviny mozku, kde je Wernickeho centrum, které slyšené -.- převede na písmeno K a pošle ho do savčího mozku. Tam ho Brockovo centrum převede na povel do prstu a pošle do motorické oblasti k Rolandově rýze. To se ale děje postupně a tak pomalu, jak pomalý je náš mozek.
B) Co se v mozku děje v danou chvíli.
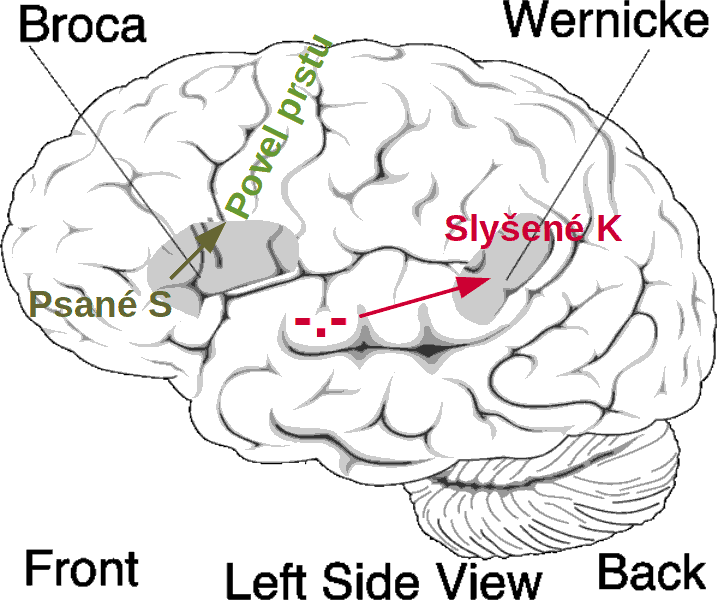
Zpracování písmen ale jde trochu urychlit tím, že plazí mozek bude zpracovávat nové písmeno, zatímco savčí mozek bude vydávat povel k napsání předchozího písmena. Takže v jedné chvíli jsou na dvou místech v mozku dvě různá písmena. První S zpracovává čelní lalok (zelený savčí), druhé K analyzuje červený plazí. Při tom všem je ale důležité nepřecházet do časové stresu, tzn. nezapínat jiná centra pro stres, zejména hypotalamus.
Na okraj poznamenávám, že nejsem neurovědec, takže ten proces bude určitě ještě o dost složitější. Proto není divu, že neurovědy patří na amerických universitách k velmi populárním.
Další dostupné procedury
Zpět ale k morseovce. Určování písmen střídáme nejprve s opisováním:
jkmorseovka.sh --opis "Pepa Smolik" # vyžaduje přesný opis tohoto textu v morse kódech
jkmorseovka.sh --opis postupne11 # generuje náhodnou skupin z prvních 11 písmen.
Víceméně jen pro logickou úplnost přikládám další procedury:
jkmorseovka.sh --diktat # diktujete v morse kodech a program vrací zvuk a zápis v latince
jkmorseovka.sh --morse "Na ja" # vytvoří a zahraje morse sekvenci: |-.|.-||.---|.-|
jkmorseovka.sh --latinka "|--|.-|--|.-|" # převádí morse znaky do latinky, čili vypíše a přehraje "mama".
Další úkoly do budoucna
Při psaní toho programu jsem pamatoval na skauty v koncentračních táborech, kteří dokázali komunikovat pomocí morse po celé budově tím, že ji tiše vyklepávali na ústřední topení. To ovšem znamená přijímat text v běžném jazyce (ne šifrované skupinky po pěti písmenech). Přijímat jednotlivá písmena ve skupinách po celých slovech a k tomu odhadovat, co dané slovo bez diakritiky vlastně může znamenat představuje mnohem větší zátěž procesní kapacity, takže předpokládám, že bude třeba snížit tempo a zvětšit pauzy mezi slovy. Ale nyní jen předesílám, že proceduru na zpracování textu v přirozeném jazyce jsem zatím nenapsal.